모델링하고 데이터 입력하여 학습시키고 평가하기까지
코드 쓸 때 고려해야 할 것들 중심으로 그 과정 살펴보기.
최종적으로 모델링하고 컴파일해서 fit 실행하여 loss와 metrics 확인하기.
1. 모델링
1.1 모델 결정
1) 순차형 Sequential : Dense layer를 순차적으로 연결하여 최종모델로 구성
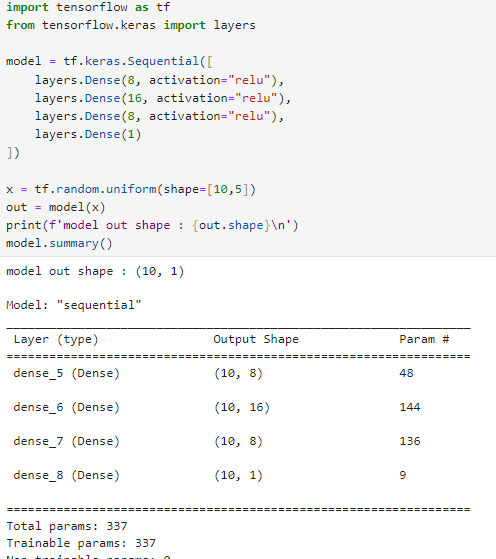
2) 함수형 Functional API : 각각의 레이어를 만들어서 함수형태로 레이어를 연결시킴.
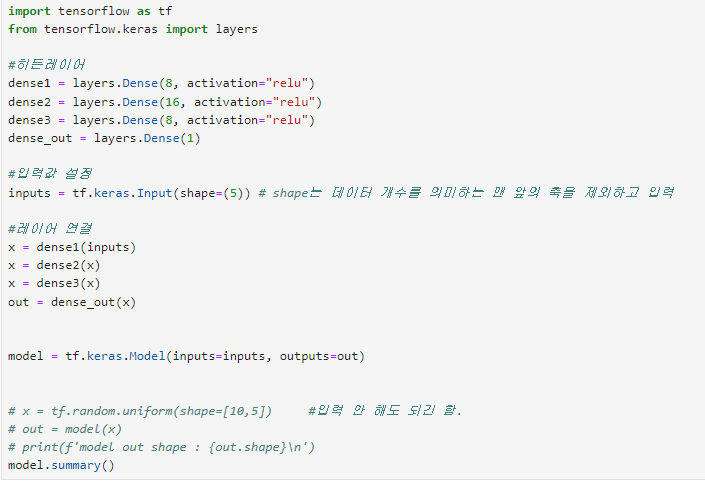
3) 객체형 Class : class 사용하여 구성.

1.2 dense layer 구성하여 연결하기.
데이터에서 매개변수, 보통 컬럼이 입력데이터가 됨.(결과 데이터 label 제외)
데이터 분석? 전처리 하여(사이킷에서 먼저 해도 되고 텐서에서 해도(tensor slice) 됨..) 나온 입력값에서 시작하여 점점 커지다가 작아져서 결과값에 맞는 수가 되도록 units 결정.
결과값의 형태(연속적 수치데이터인지 분류형인지, 분류형이면 어떤 값들이 있는지)와 활성화함수로 어떤 것을 사용할지에 따라 마지막 units의 수를 결정하는 듯.
입력사이즈와 결과레이어 구성은 임의로 정하는 게 아니라 데이터 형태?를 확인하여 맞춰야 함.

1.3 활성화함수 결정
- sigmoid: 0 ~ 1 사이의 값으로 변환(로지스틱)
- tanh: -1 ~ 1 사이의 값으로 변환
- relu: 음의 값을 0으로 변환
- softmax: 다차원에서의 sigmoid 변환(확률분포)
중간 레이어 활성화 함수, (보통 relu 사용. 학습속도 개선과 과적합 방지위함.)
마지막 예측값에 대한 활성화 함수
(결과값이 두 가지 중 하나로 표현되는 경우 (sigmoid 사용하거나, softmax 사용할 땐 클래스? 유닛? 2개),
결과값이 여러가지로 표현되는 경우 softmax 사용.)
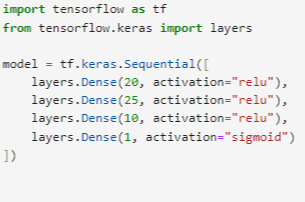

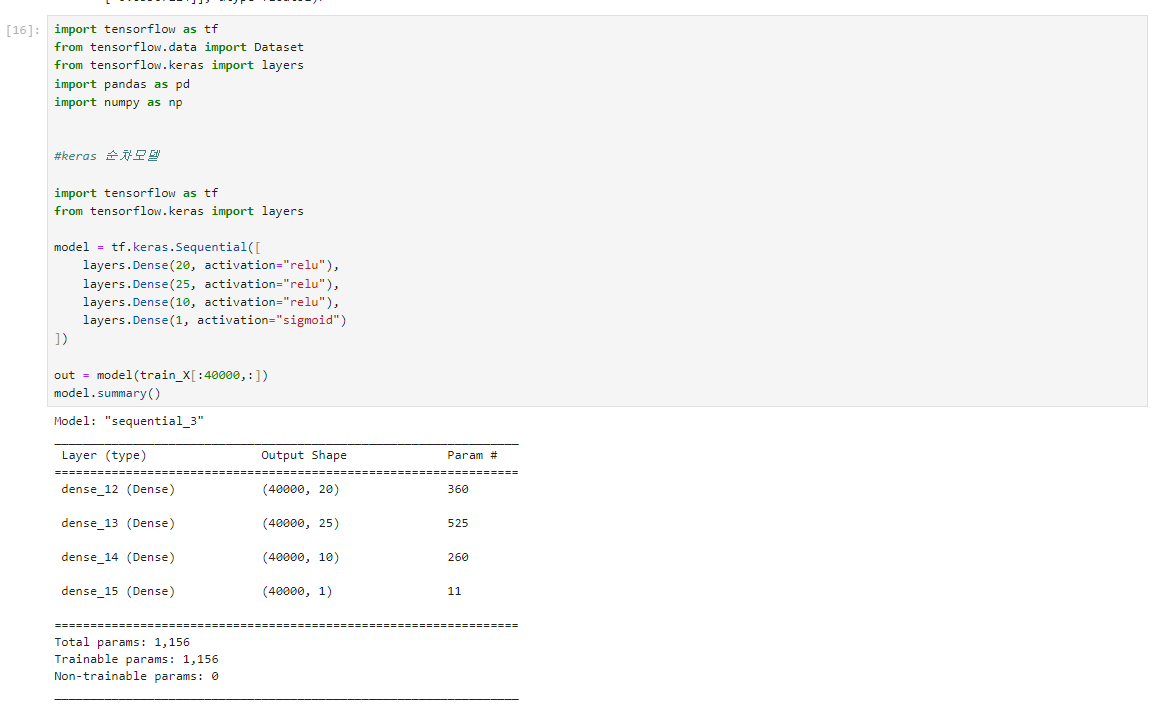
1.4 확인
model.summary 실행하여 순전파가 잘 실행?되는지 정보 뜨는거 확인.
2. 컴파일
최적화모델(경사하강법), 학습률(learning rate), 손실함수 등 결정.
model.compile(optimizer =
loss=
metrics=

2.1 경사하강법과 학습률 결정
1)경사하강법
- SGD : 확률적으로 선택된 데이터에서만 경사하강법 진행
- Momentum : 그래디언트의 이동방향(상승, 감소)를 고려하여 진행
- AdaGrad : 가중치 변화량에 따라 그래디언트 조정
- RMSProp : AdaGrad 의 0으로 수렴하는 문제 조정
- Adam : Momentum과 RMSProp의 장점을 결합
Adam을 가장 많이 사용하는 듯.
2)학습률 learning_rate
얼마나 빠르게, 얼마나 효율적으로 값을 찾아내는지에 대한 정도...?
높을수록 더 빨리 찾아낼 수 있으나 정확도가 떨어지고
낮을수록 느리게 찾아내지만 정확도가 높음.
tf.keras.optimizers.Adam(learning_rate=0.001)
2.2 손실함수
1. keras 회귀 손실함수
연속적 수치데이터의 경우(회귀모델) 예측값과 실제값 비교. 0에 가깝게 나올 수록 좋음.
- MSE (MeanSquaredError): 실제값에서 예측값을 뺀 제곱에 대한 평균. 주로 사용
- MAE(MeanAbsoluteError): 실제값에서 예측값을 뺀 절댓값에 대한 평균. matricx 확인위해 사용.
2. keras 분류 손실함수
결과값이 분류형태인 경우, 보통 softmax 활성화 함수를 사용하여 0~1사이의 확률분포 값으로 출력.
- SparseCategoriclaCrossentropy : 실제값이 index인 경우
- CategoricalCrossentroopy : 실제값이 one-hot 벡터인 경우
- BinaryCrossentropy : 실제값이 이진분류인 경우 (ex. 0 아니면 1)
2.3 metrics
- MAE : 수치형일 경우. fit 실행결과에서 0에 가까워질수록 좋음.
- accuracy : 분류형태일 경우. fit 실행결과에서 1에 가까워질수록 좋음.
3. fit 함수 사용하여 학습 실행.
fit 함수에 들어가는 변수
- 입력데이터 : 학습시킬 데이터
- 라벨데이터 :예측값과 비교할 실제값
- batch_size = 메모리 효율적 사용. 학습의 효율 위함
- epochs = 전체 데이터세트 몇 번 반복할 것 인지
- validation_data = 평가데이터 설정

loss 0에 가까워지는지, accuracy 1에 가까워지는지 확인.
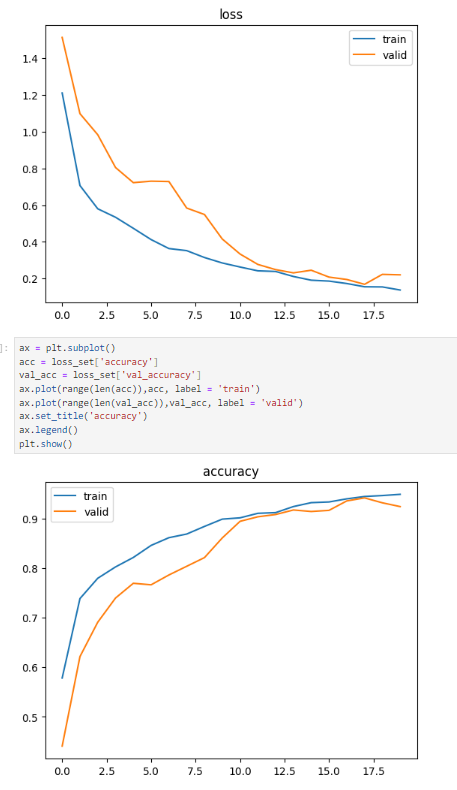
validation loss/accuracy와 비교하여 확인.
차이가 많이 나고, val_loss가 감소하다가 증가하기 시작하면 과적합이 일어나기 시작한 것.
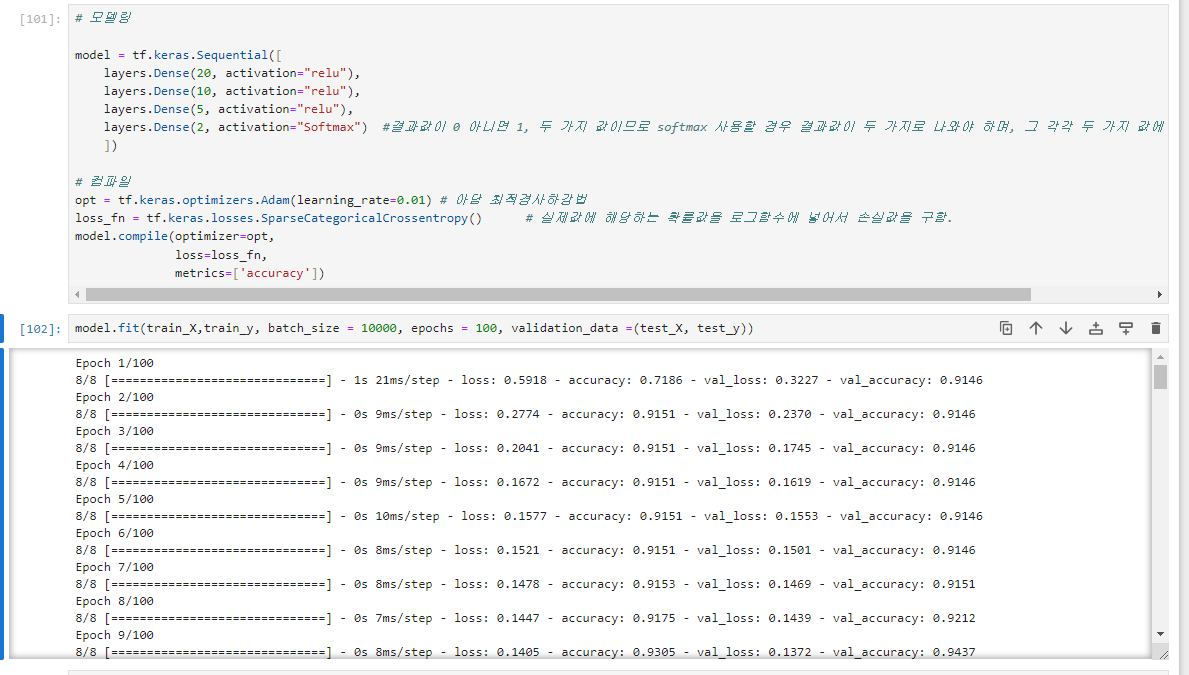
실행결과 확인하여 배치사이즈, 에포크, 학습률, 레이어 개수, units 등 조정하여 최적의 모델 구성.
(데이터 추가하거나 데이터 질 높이는 게 필요할 수도 있음.)
그래프 그려서 확인해도 좋음.
'파이썬 리뷰' 카테고리의 다른 글
| pandas dataframe 컬럼이름 변경하는 방법 (0) | 2024.01.24 |
|---|---|
| pandas 데이터프레임에서 특정 컬럼의 특정 값을 가지는 데이터만 불러오 (0) | 2024.01.12 |

